관측가능성(Observability)이란 무엇인가?
with Datadog
(아래 자료는 팀 내 세션 진행을 위해 제작한 글입니다)
관측 가능성 (Observabliity)
시스템 안에서 무슨 일이 벌어지고있는지
문제가 생겼을 때 왜 그런 일이 발생했는지
지금 상태가 정상인지 / 비정상인지
위와 같이 로그 메트릭, 트레이스 같은 신호(signal)를 통해 추론할 수 있는가를 말한다.
(≠ 모니터링한다와는 다름. 관측 가능성은 한단계 더 높은 개념임)
모니터링 ≠ 관측 가능성
모니터링(Monitoring)
미리 정한 지표를 보고
미리 정한 임계치(threshold)를 넘으면 알림
CPU가 N% 넘었는가?
에러율이 기준(정한 수치)보다 높은가?
관측 가능성(Observability)
사전에 예상하지 못한 문제도
데이터를 통해 원인을 탐색하고 설명 가능
“이 장애는 왜 발생했나요?”
“어떤 요청 경로에서 문제가 시작된건가요?”
⇒ 모니터링은 알려진 문제를 감지 , 관측가능성은 알려지지 않은 문제를 이해 에 집중하는것임.
관측가능성의 중요성
현재 KOS 시스템은 MSA / MFA로 많은 서비스를 운영중임
단일 서비스로 운영하고있지않기때문에, 어디서 문제가 시작됐는지 감으로는 파악이 아예 불가능함
또한 시스템 장애는 예상치못하게 언젠가는 발생함
이 때, 얼마나 빨리 원인을 파악하고
얼마나 정확하게 복구하느냐
- 매우 중요쓰
추가로,
관측 데이터는 단순히 서비스의 상태만이 아닌 아래 중요도도 가짐사용자 요청의 흐름 (eg. RUM)
특정 기능의 성능
릴리즈 이후 변화
관측가능성의 3대 핵심 요소(Three Pillars)
메트릭 (Metrics)
수치 기반의 시계열 데이터eg.
CPU, 메모리
요청 수, 에러율, 지연 시간(latency)
상태 변화 감지에 최적임
로그 (Logs)
사건(events) 단위의 상세 기록
eg.
에러 스택 트레이스
비지니스 이벤트 로그
맥락이 풍부하고, 무슨 일이 있었는지를 파악할 수 있음
트레이스 (Traces)
하나의 요청이 시스템을 통과하는 전체 경로
eg.
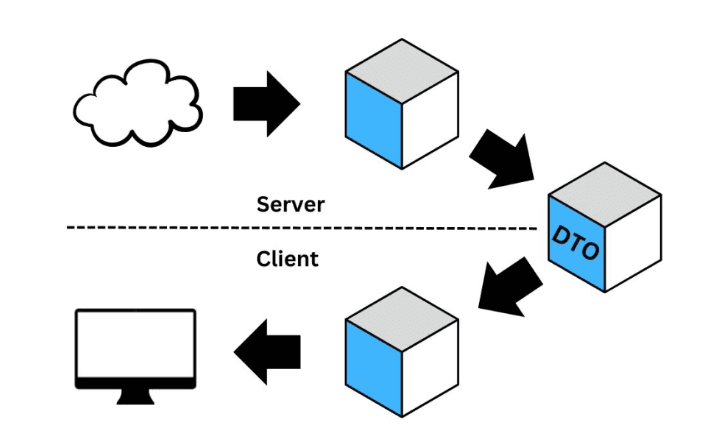
Root Client → Application API BFF → Purchase API → MongoDB
분산 시스템에서 병목과 원인 지점을 정확히 추적 가능함
그래서 관측가능성은 보통 어떻게 관리함?
계측(instrumentation)
- Application과 Infra에 메트릭 수집 / 로그 표준화 / 트레이싱 심기 를 함
중앙 수집 & 저장 (Collector)
모든 로그, 메트릭, 트레이스를 하나의 플랫폼 or 통합된 시스템으로 수집
- eg. ELK, Datadog, 별도의 Application 구현
시각화 & 탐색
대시보드
검색
서비스 맵
요청 흐름 분석
알림 & 대응
단순 임계치 알림을 넘어성
이상 징후 감지 (anomaly detection), SLO 기반 알림 구축
우리 팀은 어떻게 관측 가능성을 관리중임?

데이터독?
위 관측가능성을 올리기 위한 요구사항들을 다루기 시작하면서 등장한 SaaS 플랫폼
관측가능성의 Three Pillars를 하나의 플랫폼에서 통합
Infra → Application → UX 까지 연결 가능
데이터독 핵심 Features
Infrastructure Monitoring
서버 / 컨테이너 / k8s / 클라우드 리소스 상태 수집
CPU / Memory / Disk / Network 등 메트릭 기반 가시화
APM (Application Performance Monitoring)
요청 단위 트레이싱을 통해 서비스 간 호출 흐름 추적 가능
병목 구간, 지연 원인, 에러 발생 지점 파악
어디서 문제가 시작됐는지 확인 가눙
Log Management
Application 및 Infra 로그 중앙 수집 기능
구조화 된 로그 검색 및 필터링
메트릭/ 트레이스와 로그를 연결해 맥락(context) 있는 분석 가능
RUM (Real User Monitoring)
실제 사용자의 요청 흐름과 성능을 브라우저 단에서 관측함
사용자 경험 관점에서의 지연, 에러, 이탈 지점 파악 가능
서버 관점 아닌, 사용자 관점의 관측 가능성을 제공함
대시보드 & 알림
메트릭, 로그, 트레이스를 하나의 화면에서 시각화해줌
임계치 기반 알림을 넘어, 이상 징후(anomaly) 감지
SLO 기반 운영 지표 구성 가능
데이터독은 어떻게 수집 / 저장을 할까?
애플리케이션에서 메트릭 발생
Datadog Agent가 메트릭을 수집
- Datadog Agent: 메트릭, 로그, 트레이스를 수집하는 경량 데몬 프로세스임
- 보통 애플리케이션과 같은 호스트에서 실행함
Datadog 플랫폼으로 전송 및 저장
그 뒤 대시보드, 알림, 분석에 활용
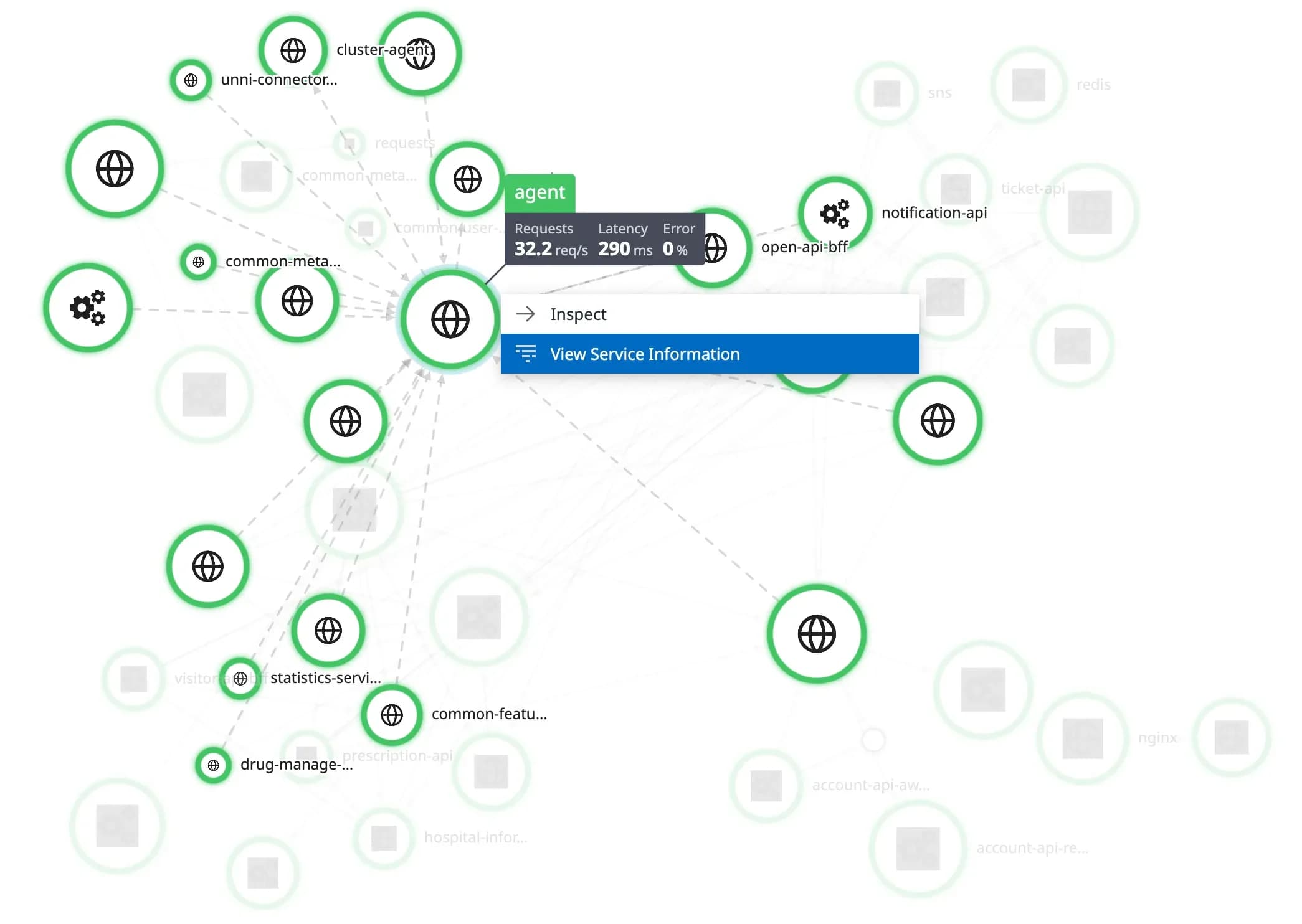
Service Map을 보면

모든 서비스들이 Agent(Datadog)을 의존하고있는것을 확인할 수 있음
왜 의존하지? 어떻게 관측 데이터 처리를 하는거지? (→ 의문이 들었음. 이걸 알아보자)
데이터독이 인프라에 어떻게 세팅되어있을까?

Datadog Agent
Kubernetes DaemonSet으로 띄움
노드 메트릭
컨테이너 메트릭
로그 파일
APM Span 수신
→ 수집된 데이터를 Datadog Saas로 전송함
즉, 모든 노드마다 Agent Pod가 1개씩 실행됨
예시)
Node
ㄴ ticket-api Pod (Java)
ㄴ purchase-api Pod (Java)
ㄴ Datadog Agent Pod
Datadog Cluster Agent

노드에 붙어있지않고, Cluster 단위로 존재함
클러스터 전체를 관리하는 컨트롤 플레인 역할을 함
Pod 생성 시 Datadog 주입 (Admission Controller) - 아래 순서대로 진행함
kubectl apply / ArgoCD sync
Kubernetes API Server
Datadog Admission Controller (Mutating Webhook)
Mutating Webhook?
Kubernetes가 리소스를 생성하기 직전에, 그 리소스의 spec을 자동으로 수정할 수 있게 해주는 훅(hook)
개발자가 작성한 YAML을
Kubernetes API Server가 최종 확정하기 전에
제3의 컨트롤러가 고쳐서 넘길 수 있게 하는 메커니즘
Pod Spec 수정 (Mutate)

Pod 생성
이미 떠있는 Pod를 건드리지않고, 앞으로 생성 될 Pod의 spec만 수정함
Deployment/Service/Pod 상태 수집
Replicas 수, Ready 여부
이벤트(Failed, CrashLoopBackOff 등)
각 컴포넌트를 통합해서 보면

Datadog Cluster Agent는 Pod 생성 시 Pod Spec을 mutate하여
APM tracer(dd-java-agent, dd-trace 등)를 주입하고
애플리케이션 Pod에서 발생한 stdout/stderr 로그는 컨테이너 런타임(eg. containerd, docker)에 의해 노드의 로그 파일로 기록된다
(Span은 데이터독 에이전트로 바로 로컬 통신으로 전달함)
Datadog Agent는 각 노드에서 이 로그 파일을 비동기적으로 tailing하고
Span/Metric은 애플리케이션으로부터 네트워크로 직접 수신하여
내부 버퍼링·샘플링 후 HTTPS를 통해 Datadog SaaS로 전송한다
(제일 얘기하고싶었던) 데이터독 Monitors 소개
Application / Infra에서 데이터가 발생하고
Datadog Agent가 이를 수집해서
Datadog SaaS에 저장하는것까지 이해함
우린 이제 저장된 데이터를 잘 활용해서 관측가능성을 올려야한다
Datadog Monitors
[관측 데이터]
↓
[조건(Condition)]
↓
[임계치 / 패턴]
↓
[상태 판단]
↓
[알림(Notification)]
데이터독 모니터는 요런 동작 모델임 (쏘 단순)
eg.
조건:
ticket-api의 HTTP 5xx 비율임계치: 5분 평균 3% 초과
결과: Slack 알림 발송
만약 모니터가 없었다면?

위와 같은 OOM Killed Event를 감지 못했을것임
HPA 등을 걸어놓아 리소스가 부족했을 때 스케일링도 중요하겠지만 OOM 발생이 정말 처리량이 많아져서 리소스가 부족해졌을 수 있지만
- 메모리 릭이나 예상하지못한 처리로 인해 문제가 발생할 수 있다
그렇기떄문에 우리는 이런 비정상 사건(events)에 대해 꼭 인지할 수 있도록 관측 가능성을 올려야함
이제 각자 모니터 만들어봐요. (15분동안)
마지막엔 프론트, 백엔드 엔지니어 모두 최근 발생했던 이슈나 개발하면서 감지하고싶었던것을 15분동안 만들어보기
그 후 각자 짧게 소개해보기