Gateway의 Connection Pool 고갈로 인한 장애, 원인은 무엇이었을까?
서론
최근 Gateway가 간헐적으로 요청을 처리하지 못하는 장애가 발생했다. 짧은 시간이었지만, 특정 시점에 에러가 집중적으로 터지면서 실제 사용자 영향도 발생했다.
처음에는 단순한 네트워크 이슈나 일시적인 트래픽 문제라고 생각했다. 하지만 로그와 지표를 하나씩 따라가다 보니, 문제의 원인은 예상보다 안쪽에 있었다.
이번 글에서는 이 장애를 어떻게 인지했고, 어떤 가설을 세웠으며, 왜 최종적으로 다운스트림의 GC Pause와 Event Loop Delay에 도달하게 되었는지를 순서대로 정리해보려고 한다. 단기적인 대응부터 장기적인 관점에서 무엇을 고민해야 했는지까지 함께 다뤄보려고한다.
문제 상황

모니터링 채널에 많은 알람이 찍히고있어, 빠르게 모니터링을 진행했다.
서비스를 라우팅하는 주 서비스인 Gateway의 에러 그래프를 보니, 특정 시점에 수천 건의 에러가 짧은 시간 동안 집중적으로 발생한것을 확인했다.
Gateway Errors Graph 이미지 첨부

로그를 확인해보니 아래 메시지가 반복적으로 찍히고 있었다. 그것도 이틀 연속, 간헐적으로 짧은 시간 동안 장애가 발생했다.
org.springframework.web.reactive.function.client.WebClientRequestException:
Pending acquire queue has reached its maximum size of 500
처음에는 단순한 네트워크 문제인가로 접근했지만, 해당 로그는 사실 WebClient의 Connection Pool 대기열이 꽉 찼다는 뜻이었다. 즉, Gateway에서 Account API(인증 서비스)로 요청을 보냈지만 커넥션을 빌릴 수 없어서 요청 자체가 실패한 상황이었다.
원인 추적
그럼 왜 커넥션 풀 고갈이 일어났을까?
에러 시점을 기준으로 Account API 지표를 확인했다.
Account API Rumtime Metrics 이미지 첨부

응답 지연: 특정 시간대에 N초 이상 증가됨
Event Loop Delay: 200ms 이상 급증함
즉, Account API 자체가 제때 응답을 돌려주지 못했고, 이로 인해 Gateway에서 커넥션이 반환되지 못한 것이다.
근본 원인
문제는 트래픽 패턴에 있었다.
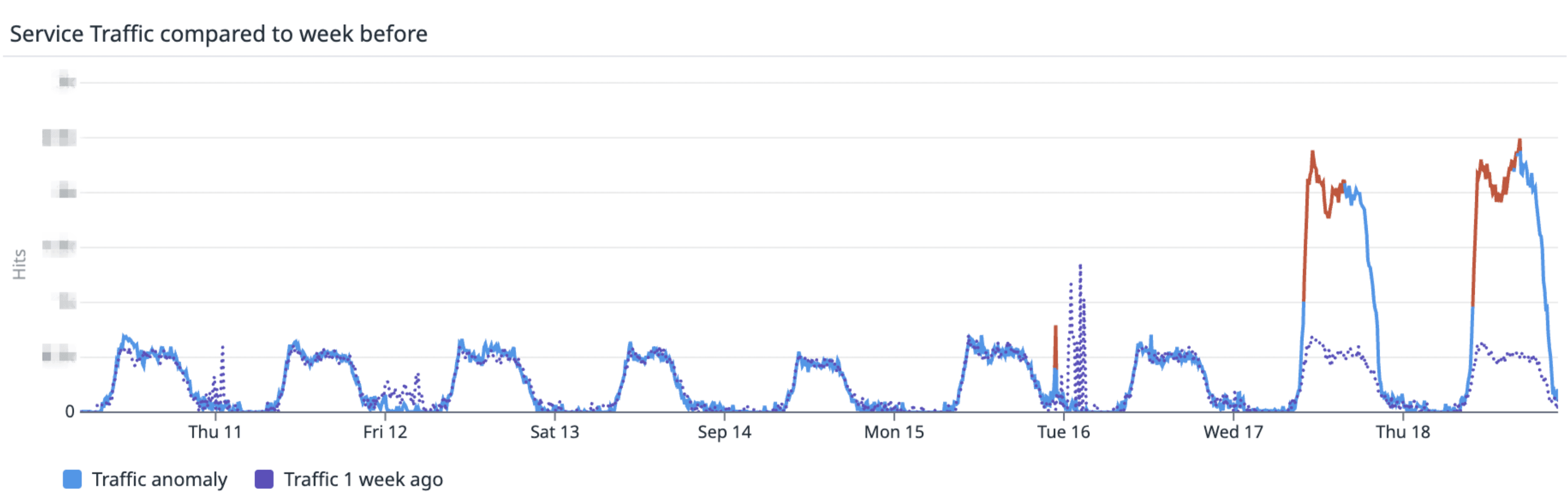
이 서비스는 특정 시간대에 이용량이 몰리는 경우는 있었지만, 예기치 못한 트래픽 급증이 발생하는 서비스는 아니었다. 그런데 주간 트래픽 그래프를 보니 평소 대비 6배 이상 급증한 메트릭을 확인했다.
Gateway 주간 트래픽 그래프

(물론, 병원에서 가장 많이 이용하는 시간대는 있지만, 예상치못한 트래픽이 갑작스레 급증하거나 하진 않는다)
Gateway의 Weekly 트래픽 지표를 토대로 급증한 요청을 집계해보니, 16일 늦은 저녁, 계정의 상태 변경을 최신화하기위해 클라이언트의 폴링 로직이 배포된 영향이였다.
대응 시작

일단 문제 상황을 팀원분들께 공유했고, 세번째 프로덕션 장애를 막기 위해 다양한 논의를 스레드에서 진행했다. 이 논의 과정에서 빠르게 단기적 방어 전략을 세웠고, 응급 조치를 진행했다. (단기적/ 장기적 전략을 어떻게 세웠는지는 아래에서 구체적으로 다룰 예정)
왜 Event Loop Delay가 그렇게 크게 발생했을까?
이제부터 Node.js 런타임 내부 동작, GC Pause, 그리고 Event Loop Delay에 대해 살펴보려한다.
문제의 본질을 이해하기위해서는 Node JS의 구조적 특성을 이해해야된다 생각한다
Node.js 동작 원리
Node.js 애플리케이션은 단일 스레드 기반 이벤트 루프 모델로 동작한다.
즉, 모든 요청 처리는 결국 이벤트 루프라는 한 줄짜리 실행 트랙 위에서 순차적으로 흘러간다.
“이벤트 루프가 잠깐이라도 중단되면, 동시에 들어오는 요청들이 모두 영향을 받는다.”
이번 장애 상황의 핵심도 바로 이 부분이었다.
libuv와 이벤트 루프의 내부를 열어보면
Node.js는 구글의 V8 자바스크립트 엔진 위에서 동작하며, 비동기 I/O 처리는 libuv라는 C 언어 레벨의 이벤트 루프 라이브러리가 담당한다
libuv의 루프를 코드에서 단순화해보면 아래와 같다
// libuv 내부 구조를 단순화해보면
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
while (loop->active_handles > 0) {
uv__update_time(loop); // 현재 tick 시간 갱신
uv__run_timers(loop); // setTimeout / setInterval 콜백 실행
uv__run_pending(loop); // I/O 콜백 실행
uv__run_idle(loop); // Idle 핸들 실행
uv__io_poll(loop, timeout); // epoll/kqueue/select 대기 및 이벤트 감지
uv__run_check(loop); // setImmediate 콜백 실행
uv__run_closing_handles(loop);// Close 이벤트 처리
}
return 0;
}
이 루프가 바로 Node.js 이벤트 루프의 핵심이다.
V8이 자바스크립트로 코드를 실행하면, 비동기 호출(fs.readFile, fetch, setTimeout 등)은 libuv의 큐에 작업으로 등록된다. 그리고 libuv는 OS의 이벤트 시스템(epoll, kqueue, IOCP 등)을 활용해 이벤트를 감시하고, 완료된 작업을 다시 V8으로 콜백 형태로 전달한다.
각 Phase의 실제 흐름은
위 루프를 JS 개발자 입장에서 좀 더 가깝게 표현하면 다음과 같다.
// pseudo-code로 작성하면
while (true) {
timersPhase(); // setTimeout / setInterval
ioCallbacksPhase(); // I/O 콜백 (예: DNS, FS 등)
idlePreparePhase(); // 내부 준비 작업
pollPhase(); // 이벤트 감시 및 실행 (핵심)
checkPhase(); // setImmediate 실행
closePhase(); // 소켓 close, cleanup
}
이 과정에서 pollPhase() 가 핵심인데, pollPhase() 순서에서 실제 네트워크 소켓이나 파일 I/O 결과를 기다린다.
이 과정은 크게 다음 두 가지 상태를 오간다.
이벤트가 존재할 때: 즉시 콜백 실행
이벤트가 없을 때: 대기 (idle state)
이 대기 시간은 곧 이벤트 루프가 쉬는 시간이며, 만약 이 시점에서 CPU-bound 작업이 들어오면 (eg. json parsing, encryption, 대용량 연산 등)이 들어오면 루프가 한 tick 동안 돌아오지 못하고 Event Loop Delay가 발생한다.
tick과 delay의 관계는
Node.js 내부적으로는 매 tick마다 현재 시간(uv__update_time)을 기록하고, 다음 tick 시작 시점과 비교하여 지연을 측정한다.
아래와 같은 방식으로 Event Loop Delay를 실험해볼 수 있다
const start = performance.now();
setInterval(() => {
const delay = performance.now() - start - 100;
if (delay > 50) console.log(`Event loop delayed by ${delay.toFixed(2)}ms`);
}, 100);
// cpu bound 작업 수행
setTimeout(() => {
const end = Date.now() + 500; // 500ms 동안 block 해보기
while (Date.now() < end);
}, 2000);
이 코드를 실행하면 약 2초 후부터 “Event loop delayed by ~500ms” 같은 로그가 찍히는것을 확인할 수 있다.
즉, JS 스레드가 500ms 동안 block 되었기 때문에, 루프가 제때 돌아오지 못한 것이다.
V8 ↔ libuv의 협업 구조는
이벤트 루프는 단순한 무한 반복문이 아니다.
사실은 V8과 libuv의 협업 구조로 이루어져 있다.
+------------------------------------------------------+
| JavaScript Code |
| (async/await, Promise, callbacks 등) |
+-------------------------------┬----------------------+
│
▼
+------------------------------------------------------+
| V8 Engine |
| - 실행 컨텍스트 관리 (Execution Context) |
| - 메모리 / Heap 관리 (Garbage Collection) |
| - JS 코드 → 바이트코드 컴파일 및 실행 |
+-------------------------------┬----------------------+
│
▼
+------------------------------------------------------+
| libuv Layer |
| - Event Loop (uv_run) |
| - Timer Queue (setTimeout, setInterval) |
| - Async I/O Polling (epoll, kqueue, IOCP) |
| - Thread Pool (비동기 CPU-bound 작업 처리) |
+-------------------------------┬----------------------+
│
▼
+------------------------------------------------------+
| OS Kernel & System Calls |
| - 네트워크 소켓, 파일 I/O, 타이머, 시그널 관리 |
| - epoll/kqueue/select 기반 이벤트 감시 |
+------------------------------------------------------+
즉, Node.js에서 비동기 I/O는 실제로 JS 스레드가 직접 처리하지 않는다.
libuv의 이벤트 루프가 OS 커널 이벤트를 감시하고 완료된 이벤트를 콜백 형태로 V8에 전달한다.
하지만 중요한 점은, GC Pause나 CPU-bound 연산은 V8 엔진 내부에서 발생하기 때문에, 이때는 libuv가 아무리 준비되어 있어도 JS 스레드가 멈추기 때문에 콜백을 처리할 수 없다. 그게 바로 Event Loop Delay의 근본 원리이다.
최종으로 이벤트 루프의 흐름을 요약하면 아래와 같다.
V8이 JS 코드를 실행한다
비동기 작업은 libuv의 큐로 위임된다
libuv는 OS 레벨에서 이벤트를 기다린다
완료된 작업을 다시 JS 콜백 큐에 push한다
GC, CPU 작업 등으로 JS 스레드가 막히면, 다음 tick이 지연된다
여기서 지연된 시간이 바로 Event Loop Delay 이다.
이 사이클은 보통 몇 밀리초도 걸리지않는데, 특정 시점에 한 tick이 수백 밀리초 이상 늦어진다면, 그 순간 들어오는 모든 요청이 줄줄이 밀리 시작한다. (이게 이번 장애의 핵심이였음)
그래서 Event Loop Delay는 이벤트 루프가 제때 tick을 돌지 못했을 때 발생한다.
예를 들어,
원래는 10ms 단위로 루프가 돌아야 하는데
어떤 작업이 200ms를 점유했다면
그 순간 event loop delay는 190ms로 기록되게되는것이다
즉, delay 지표는 이벤트 루프가 얼마나 늦게 돌고 있는가를 보여주는 신호(signal)이다.
이번 Account API의 장애 시점에서 이 값이 200ms 이상 치솟은 건, 루프가 그만큼 멈췄다는 의미인것이다.
그래서 V8의 GC가 Event Loop를 왜 멈춘게 한건데? (GC Pause)
Node.js의 자바스크립트 실행은 V8 엔진 위에서 수행된다. V8은 단순히 JS를 실행하는 엔진이 아니라, 실행 컨텍스트와 메모리(Heap)를 직접 관리하는 런타임 시스템이다.
즉, V8은 다음 두 가지 책임을 동시에 가진다.
JS 코드를 빠르게 실행한다.
사용이 끝난 객체를 찾아서 메모리를 회수한다.
이 두 번째 단계, 바로 Garbage Collection(GC)이 이번 장애의 숨은 주범이었다.
V8의 Heap 구조
V8의 메모리는 크게 두 세대(Generation)로 나뉜다.
+-----------------------------------------+
| Heap |
+-------------------+---------------------+
| Young Generation | Old Generation |
| (새 객체, 임시값) | (오래된 객체) |
+-------------------+---------------------+
Young Generation
새로 생성된 객체들이 저장되는 공간이다.
메모리가 작고, GC가 자주 발생하지만 빠르다.
여기서 수행되는 GC를 Minor GC라고 한다.
Old Generation
여러 번의 GC를 견뎌 살아남은 객체들이 옮겨지는 공간이다.
용량이 크고, GC는 느리지만 횟수는 적다.
여기서 수행되는 GC를 Major GC (또는 Mark-Sweep-Compact)라고 한다.
V8의 GC는 단순히 쓰지 않는 메모리를 지운다 수준으로 그치지않는다.
실제로는 아래와 같은 단계를 거친다.
Mark Phase (마킹 단계)
루트 객체(Global, Stack 등)에서 참조 가능한 모든 객체를 따라가며 표시(mark)한다.
즉, “아직 살아있는 객체”를 식별한다.
Sweep Phase (제거 단계)
- 마킹되지 않은 객체(참조되지 않는 객체)를 찾아 메모리에서 제거한다.
Compact Phase (압축 단계)
- 남은 객체들을 Heap의 앞부분으로 모아 메모리 단편화(Fragmentation)를 줄인다.
이 Compact 단계가 바로 Stop-the-World(STW)의 핵심이다
이때 JS 실행이 완전히 멈춘다. 왜냐면, 객체의 위치가 바뀌면 모든 참조 포인터를 다시 계산해야 하기 때문이다.
Stop-the-World(STW)란?
STW는 GC가 실행되는 동안 JS 실행이 완전히 중단되는 구간을 말한다.
즉, 그 순간 이벤트 루프도 멈춘다.
JS 실행 중 → [GC Start] → (모든 JS 코드 중단) → [GC End] → JS 실행 재개
아래는 간단히 그 시점을 시각화한 예시다
|---- JS 실행 ----|■■■■■■■■■■■■■■|---- JS 실행 ----|
↑
GC Pause 구간
이 Pause가 50ms 정도라면 거의 체감이 안 된다.
하지만 200ms~500ms 이상 길어지면, Event Loop Delay로 이어진다.
실제로 어떻게 Delay가 측정되었나?
V8 엔진은 내부적으로 GC 수행 시간을 측정하며,
Node.js는 eventLoopDelay 또는 gcDuration 같은 메트릭으로 이를 노출한다.
장애 당시 Account API의 지표에서는 다음 패턴이 관측되었다.
GC Pause Duration: 40~50ms
Event Loop Delay: 200ms 이상
이는 단순히 GC 하나가 느린 게 아니라, 여러 GC Pause가 연속적으로 발생하면서 이벤트 루프의 tick 주기를 밀어버린 상황이었던것이다.
그런데 왜 Major GC가 자주 발생했나?
V8이 Major GC를 수행하는 이유는 단순하다. 바로 Old Generation 영역이 꽉 찼기 때문이다.
이 영역은 주로 다음 이유로 가득 찬다.
짧은 주기의 대량 객체 생성
JSON 직렬화/역직렬화
DTO 변환, 복사 등
GC가 도달하지 못하는 객체 참조 유지
- 전역 캐시나 클로저 내부의 오래된 참조
메모리 해제 타이밍 불일치
- JS는 객체 참조가 사라져야만 GC 대상이 됨
즉, 트래픽이 급증하고 JSON 변환이 반복되는 상황에서는 메모리 할당/해제가 폭증하면서 Major GC가 더 자주 일어나게 된다.
gateway 흐름을 도식으로 살펴보면

이걸 앞선 Gateway 문제와 연결해보면 이렇게 된다.
Account API에서 GC Pause → Event Loop Delay 발생
응답이 지연됨 → Gateway WebClient가 커넥션을 붙잡고 대기
Pool에 여유 커넥션이 없음 → Pending Queue로 요청 밀림
Queue까지 한계치 도달 →
Pending acquire queue has reached its maximum size에러 발생클라이언트의 요청(Request)은 실패 응답(5xx)를 받게됨
즉, Gateway에서 본 에러의 근본 원인은 Account API 내부의 이벤트 루프 지연이었다.
그런데 인증 서버(account-api)는
Account API는 서비스의 모든 요청이 반드시 거쳐야 하는 계정/보안 서비스이다. 여기서 이벤트 루프가 멈추면, 사실상 서비스 전체가 멈추는 것과 같다.
일반적인 데이터 집중적인 마이크로 서비스라면 Circuit Breaker로 요청을 차단하는 선택을 할 수 있겠지만, Account API는 그럴 수조차 없었다. (물론 회로 차단을 세밀히 조정하면 효과는 볼 수 있겠지만)
결국 GC Pause와 Event loop Delay를 줄이는것이 서비스 안정성의 핵심 과제라고 생각됐다.
단기적인 대응 전략
이번 장애에서 취한 응급 대응은 크게 두 가지였다.
타임아웃 단축 (fail fast)
기존 Gateway WebClient의 타임아웃이 5초였다.
이 설정 때문에 Account API가 응답하지 못하면 커넥션을 최대 5초 동안 붙잡게 되었고, 그 결과 커넥션 풀 고갈로 이어졌다.
타임아웃을 단축해 Fail-Fast 전략으로 전환함으로써, 지연이 전체 시스템에 전파되는 걸 우선적으로 차단하도록했다.
요 전략은 에러율은 순간적으로 증가할 수 있지만, 풀 고갈로 인한 연쇄 장애를 막는 데는 효과적이 방어수단이라고 생각했다.
Account API Scale-out
Account API는 모든 서비스 요청의 관문 역할을 하기 때문에, 단일 인스턴스에서 Event Loop가 멈추는 순간 전체 서비스 장애로 이어질 수 있다
따라서, Account API의 Pod 수를 기존 대비 2배로 확장해 트래픽을 분산했다
이를 통해 특정 인스턴스에서 GC Pause가 발생하더라도, 그 영향이 전체 장애로 확산되는 상황은 방지할 수 있었다
참고로 이 시점에서 HPA를 적용하는 선택지도 고려할 수 있다.
다만, 이번 상황에서는 이미 장애가 발생한 이후였고 event loop delay는 cpu 사용률처럼 즉각적인 scale 지표로 삼기엔 애매한 특성이 있어 수동 scale out으로 빠르게 대응하는 쪽을 선택했다.
장기적인 개선 전략
단기적인 대응으로 일시적인 안정성은 확보했지만, Event Loop Delay와 GC Pause는 언젠가/ 언제든지 다시 반복될 수 있다. 따라서 장기적으로 아래와 같은 접근이 필요하다고 판단했다.
이벤트 루프 지연에 대한 관측성 확보
- Event Loop Delay 지표를 Monitor Alert 로 추가하여, 100ms 이상의 지연이 발생할 경우 즉시 인지할 수 있도록한다
메모리 프로파일링 및 최적화
heap snapshot, heamdump 등을 활용해 어떤 객체가 주로 메모리를 점유하는지 파악한다
특히 json 직렬화/역직렬화 과정에서 불필요한 객체 생성/ 복사가 있다면 개선 대상으로 본다
GC 튜닝
Node.js 실행 시
—max-old-space-size옵션으로 Heap 크기를 조정해 Major GC 발생 빈도를 줄인다다만 heap 크기를 무작정 키우면 STW 시간이 함께 늘어날 수 있기때문에, 애플리케이션이 어떤 객체를 얼마나 자주 생성하고, 그 객체들이 얼마나 오래 살아남는지와 같은 메모리 할당 패턴을 파악해보고 heap 크기를 조정하는것이 필요하다
이를 위해, 관측성 도구에 내장된 기능(eg. datadog profiling) 또는 pprof 툴같은걸 이용해서 실제 메모리 할당 그래프와 GC 발생 주기의 상관관계를 추적하는 것이 중요하다 (필자는 datadog 기능 이용하였음)
스케일링 전략 (HPA 관점)
CPU 사용률 기반 HPA는 GC Pause나 Event Loop Delay를 직접적으로 해결하지는 못한다
하지만 지속적인 트래픽 증가 상황에서는 완충 역할을 할 수 있다
장기적으로 아래 내용을 고려해보고있다
CPU / Memory 기반 HPA로 기본적인 트래픽 대응
Event Loop Delay는 알람 및 운영 판단 지표로 활용
Delay 증가 시 캐싱, 트래픽 차단, 수동 스케일 아웃과 같은 대응 시나리오 준비
캐싱 전략
동일한 계정 검증, IP 확인, MFA 상태 조회 등이 반복되기때문에, 캐시 계층을 두어 불필요한 CPU 및 메모리 소모를 줄인다
- 실제로 모든 API들이 Account API를 거치면서, 최소 3회 이상의 DB Query가 발생하고 있었기 때뭉네 이 부분은 GC 부담을 줄이는 데에도 직접적인 효과가 있을 것으로 판단했다
마무리
이번 장애를 겪으면서 다시 한 번 느낀 건, Node.js의 단일 스레드 모델은 단순해 보이지만 결코 단순하지 않다는 점이었다.
이벤트 루프의 한 틱이 밀리는 순간, 그 영향은 생각보다 빠르게, 그리고 넓게 퍼진다. (게다가 인증 서비스였어서) 겉으로는 Gateway의 커넥션 풀 문제처럼 보였지만, 실제 원인은 훨씬 아래 계층에서 조용....하게 쌓이고 있었다.
장애를 마주했을 때 무작정 스케일을 늘리는 선택도 필요할 수 있다. 하지만 그보다 더 중요한 건, 내가 만든 서비스가 내부에서 어떻게 돌아가고 있는지 이해하고 있는가라는 질문이라고 생각한다.
이번 경험이, Event Loop Delay나 GC Pause를 지표에서 처음 마주했을 때, “왜 이런 현상이 나오는 걸까?”를 한 번 더 고민해보는 계기가 되었으면 좋겠다는 생각을 하며 마무리한다.